Definición, claves clúster y partición – Apache Cassandra – parte 1
January 29, 2018
Tiempo total: 48 días con 9:40:22 hrs
Es una base de datos Open Source NoSQL. Fue inicialmente desarrollada por Facebook y utilizada por Twitter. Cassandra utiliza una arquitectura distribuida, es decir que cada servidor del clúster tendrá una instancia (nodo), esto le permite almacenar y manipular grandes cantidades de información.
![]()
Sus principales características son:
- Es un sistema descentralizado: todos los nodos tienen el mismo rol, no existe un nodo maestro.
- Replicación: en el clúster y en múltiples datacenters.
- Escalabilidad lineal: las lecturas y escrituras aumentan a medida que se agregan más nodos al clúster.
- Tolerancia a fallas: la información puede estar en más de un nodo (redundancia) y en múltiples centros de datos.
- Consistencia: posibilidad de obtener el registro con la fecha de grabación de un nodo, del clúster o de todos los datacenter.
Almacenamiento de registros en Cassandra
Profundizando más en su funcionamiento, a continuación una explicación básica pero fundamental al momento de diseñar la tabla que almacenará información.
Es necesario mencionar que Cassandra está diseñada para almacenar grandes cantidades de información, las aplicaciones más comunes son: redes sociales y telemetría (varias escrituras cada intervalo de tiempo).
Una base de datos en Cassandra es representada por una keyspace, que almacenará las tablas. Para crear las tablas será necesario definir la clave partición y la clave clúster:
- Clave de partición: su función es definir el nodo en donde se almacenará el registro. Esto lo hace utilizando una función hash.
- Clave de clúster: Una vez definido el nodo en que se almacenará el registro, el siguiente paso será guardarlo de acuerdo al orden definido por el usuario, la clave clúster idealmente debe de ser una marca de tiempo (timestamp).
Espera un momento! No entiendo ¿cómo aplico esos conceptos al momento de diseñar mis tablas?
De acuerdo a las características de cada escenario (cada aplicación). Por ejemplo, supongamos un clúster de 10 nodos utilizado para almacenar 1GB de información cada día. Nuestra aplicación es Twitter y cada Tweet tendrá: el id del usuario, la marca de tiempo y el texto. Esta tabla la podemos definir:
CREATE TABLE tweet (
usuario bigint,
timestamp timestamp,
tweet text,
PRIMARY KEY (usuario, timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC);
En la tabla anterior el id de usuario será la clave partición, esto significa que cuando un nodo reciba un registro para escribir aplicará la siguiente función hash(usuario) = {1, 2, 3, …, 10}, es decir que los posibles valores serán del 1 al 10 (nodos en el clúster). De esta manera todos los registros de un usuario estarán en un solo nodo.
La clave de clúster es la que se encarga de ordenar los registros en el nodo, en este caso de manera descendiente (el más reciente de primero).
Clave clúster
Cada nodo Cassandra almacenará los registros pertenecientes a diferentes claves de partición (en nuestro ejemplo pueden haber 10 nodos pero 10,000 usuarios). Entonces, Cassandra define el almacenamiento por clave partición en forma horizontal.
¿Cómo funciona? Para describir esto, a nuestra tabla ejemplo le vamos a agregar más campos para tener un mejor detalle de este concepto:
CREATE TABLE tweet (
usuario bigint,
timestamp timestamp,
tweet text,
dispositivo text,
idioma text,
ip text,
PRIMARY KEY (usuario, timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC);

En el ejemplo anterior observamos que para cada clave partición (usuario) se creará una fila con sus tweets, ordenados de forma descendiente definidos por la clave clúster (timestamp). En este caso los valores de cada celda serán los campos tweet, dispositivo, idioma e ip.
Cada tabla tendrá entones una fila con N registros para cada usuario. Espera un momento! ¿cuál es la capacidad máxima de registros por fila? Teóricamente es de 2 billones.
Si los 2 billones de registros por clave partición los planeamos usar en un mes, significa que por minuto tendríamos un límite de 4.6 millones de registros. A continuación la siguiente tabla:
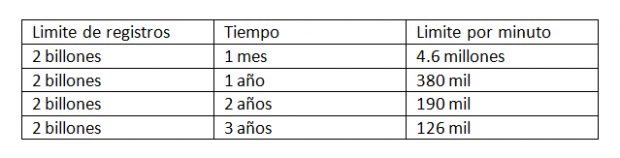
Personas con más experiencia en el manejo de big data estiman que almacenar grandes números de registros para cada clave partición provocará un impacto negativo en el rendimiento de Cassandra.
Para optimizar Cassandra, es necesario agregar más valores a la clave de partición, esto lo podemos hacer separando cada usuario por mes (lógicamente a cada mes le debe preceder un año):
CREATE TABLE tweet (
usuario bigint,
year int,
month int,
timestamp timestamp,
tweet text,
dispositivo text,
idioma text,
ip text,
PRIMARY KEY ((usuario, year, month), timestamp)
) WITH CLUSTERING ORDER BY (timestamp DESC);
La clave de partición (usuario, año, mes) crea diferentes filas de registros por cada usuario/año/mes. La tabla ahora será de la siguiente forma:

La función hash de la clave partición será: hash(usuario, año, mes) = {1,2,3,…,10}.
Consultando los datos con CQLSH
Cassandra utiliza CQL (Cassandra Query Language) o básicamente SQL muy limitado. Para acceder a la línea de comandos de Cassandra utilizamos el siguiente comando en Linux (En otra publicación explicaré como hacer la instalación en múltiples servidores Linux):
>cqlsh {ip}
Para poder consultar la información es obligatorio definir las claves partición (si la tabla las usa) y la clave clúster.
En el siguiente ejemplo para obtener los tweets enviados por un usuario en los últimos 10 minutos debemos especificar el usuario, año, mes y marca de tiempo:
SELECT * FROM tweet WHERE usuario = 100 AND year = 2018 AND month = 1 AND timesteamp > ‘2018-01-28 20:12:00’ AND timestamp <= ‘2018-01-28 20:22:00’;
Si queremos obtener todos los usuarios utilizando DISTINTC, los obtendremos pero con los campos año y mes, caso contrario no funcionaria:
SELECT DISTINCT usuario, year, month FROM tweet;
Es fácil entender porque es necesario especificar los valores de las claves de partición y clúster: Cassandra debe obtener la información de los nodos del clúster y debe poder servir los datos lo más rápido posible.
En el código de nuestra aplicación deberemos de hacer las implementaciones necesarias para que este proceso sea transparente para el usuario final.
Video
Recomiendo este video, fue el video más claro, profesional y con la información necesaria que ayuda mucho a conceptualizar el funcionamiento de Cassandra:
Referencias electrónicas
[https://es.wikipedia.org/wiki/Apache_Cassandra]
[https://docs.datastax.com/en/cql/3.1/cql/cql_reference/refLimits.html]
[https://www.youtube.com/watch?v=465hYrXabFc]
[https://upload.wikimedia.org/wikipedia/commons/thumb/5/5e/Cassandra_logo.svg/2000px-Cassandra_logo.svg.png]
